配置 salt
配置
客户端配置
客户端配置比较简单,只需要配置一下server的地址就可以了,复杂的配置等到以后遇到的适合在进行介绍
# 配置salt服务端地址 |
服务端操作
# 查看有哪些client发起了验证请求 |
简单验证执行命令
远程执行命令
salt aws-bj* cmd.run uptime |
下篇预告
系列文章
客户端配置比较简单,只需要配置一下server的地址就可以了,复杂的配置等到以后遇到的适合在进行介绍
# 配置salt服务端地址 |
# 查看有哪些client发起了验证请求 |
salt aws-bj* cmd.run uptime |
最新的salt包会发布在 Ubuntu saltstack PPA。如果你的系统中有add-apt-repository 工具,可以通过一条命令添加仓库并导入PPA key:
add-apt-repository ppa:saltstack/salt |
如果没有找到add-apt-repository命令可以执行下面的命令进行安装
可能也需要安装下面的包
echo deb http://ppa.launchpad.net/saltstack/salt/ubuntu `lsb_release -sc` main | sudo tee /etc/apt/sources.list.d/saltstack.list |
apt-get update |
apt-get install salt-master salt-minion salt-syndic |
apt-get install salt-minion |
ZeroMQ 4 在 Ubuntu 14.04 以上版本已经与系统集成。因此Ubuntu 12.04 LTS 之前的版本需要升级到ZEROMQ 4
利用iptables-save命令可以将iptable规则保存到一个持久化存储的目录中,不同的系统保存的目录也有所不同(IPv4):
Debian/Ubuntu: iptables-save > /etc/iptables/rules.v4
RHEL/CentOS: iptables-save > /etc/sysconfig/iptables
保存之后,可以通过iptables-restore命令载入(IPv4):
Debian/Ubuntu: iptables-restore < /etc/iptables/rules.v4
RHEL/CentOS: iptables-restore < /etc/sysconfig/iptables
上面是针对IPv5的规则,如果你有使用IPv6的规则,通常需要执行下面对应的IPv6保存和恢复的命令(IPv4:
Debian/Ubuntu: ip6tables-save > /etc/iptables/rules.v6
RHEL/CentOS: ip6tables-save > /etc/sysconfig/ip6tables
注意: 这种方式只是保存规则和恢复的一种方式,并不是说保存规则后下次启动就会自动加载。一定要记住这点,如果要想系统启动后自动加载请看下面的方式。
从 Ubuntu 10.04 LTS (Lucid) 和 Debian 6.0 (Squeeze) 版本开始,可以通过安装一个名为 “iptables-persistent” 的包,安装后它以守护进程的方式来运行,系统重启后可以自动将保存的内容加载到iptables中。当然前提也是需要先保存规则。
apt-get install iptables-persistent |
service iptables-persistent save |
RHEL/CentOS 提供了简单的方式来持久化存储iptables规则,可以直接通过iptables服务的命令来完成:
chkconfig --list | grep iptables |
IPv4规则信息会保存到 /etc/sysconfig/iptables 文件中,IPv6 规则保存到 /etc/sysconfig/ip6tables 文件中。 必须执行service iptables save 命令才会保存,保存后系统重启后会自动加载。
db01 (主)
db02 (从)
| 时间 | 备份类型 |
|---|---|
| 00:01 | 全量备份 |
| 01:01 | 增量备份(当天首次) |
| 02:01~23:01 | 增量备份 |
随着数据量的增加,全量备份可以做成每周一次,每2~8小时一次增量备份
db{01,02}:/data/backup/{full,incremental}/
backup/ |
# Info : 数据库备份 |
/root/bin/bakdb.sh
|
innobackupex --user=root --defaults-file=/usr/local/mysql/my.cnf --apply-log /data/backup/full/2015-08-16 |
innobackupex --defaults-file=/usr/local/mysql/my.cnf --user=root --apply-log --redo-only /data/backup/full/2015-08-16 |
原文在此,实用总结。
这里是我过去几年中编写的大量 Go 代码的经验总结而来的自己的最佳实践。我相信它们具有弹性的。这里的弹性是指:
某个应用需要适配一个灵活的环境。你不希望每过 3 到 4 个月就不得不将它们全部重构一遍。添加新的特性应当很容易。许多人参与开发该应用,它应当可以被理解,且维护简单。许多人使用该应用,bug 应该容易被发现并且可以快速的修复。我用了很长的时间学到了这些事情。其中的一些很微小,但对于许多事情都会有影响。所有这些都仅仅是建议,具体情况具体对待,并且如果有帮助的话务必告诉我。随时留言:)
多个 GOPATH 的情况并不具有弹性。GOPATH 本身就是高度自我完备的(通过导入路径)。有多个 GOPATH 会导致某些副作用,例如可能使用了给定的库的不同的版本。你可能在某个地方升级了它,但是其他地方却没有升级。而且,我还没遇到过任何一个需要使用多个 GOPATH 的情况。所以只使用单一的 GOPATH,这会提升你 Go 的开发进度。
许多人不同意这一观点,接下来我会做一些澄清。像 etcd 或 camlistore 这样的大项目使用了像 godep 这样的工具,将所有依赖保存到某个目录中。也就是说,这些项目自身有一个单一的 GOPATH。它们只能在这个目录里找到对应的版本。除非你的项目很大并且极为重要,否则不要为每个项目使用不同的 GOPATH。如果你认为项目需要一个自己的 GOPATH 目录,那么就创建它,否则不要尝试使用多个 GOPATH。它只会拖慢你的进度。
如果在某个条件下,你需要从 for-select 中退出,就需要使用标签。例如:
func main() { |
如你所见,需要联合break使用标签。这有其用途,不过我不喜欢。这个例子中的 for 循环看起来很小,但是通常它们会更大,而判断break的条件也更为冗长。
如果需要退出循环,我会将 for-select 封装到函数中:
func main() { |
你还可以返回一个错误(或任何其他值),也是同样漂亮的,只需要:
// 阻塞 |
这是一个无标签语法的例子:
type T struct { |
那么如果你添加一个新的字段到T结构体,代码会编译失败:
type T struct { |
如果使用了标签语法,Go 的兼容性规则(http://golang.org/doc/go1compat)会处理代码。例如在向net包的类型添加叫做Zone的字段,参见:http://golang.org/doc/go1.1#library。回到我们的例子,使用标签语法:
type T struct { |
这个编译起来没问题,而且弹性也好。不论你如何添加其他字段到T结构体。你的代码总是能编译,并且在以后的 Go 的版本也可以保证这一点。只要在代码集中执行go vet,就可以发现所有的无标签的语法。
如果有两个以上的字段,那么就用多行。它会让你的代码更加容易阅读,也就是说不要:
T{Foo: "example", Bar:someLongVariable, Qux:anotherLongVariable, B: forgetToAddThisToo} |
而是:
T{ |
这有许多好处,首先它容易阅读,其次它使得允许或屏蔽字段初始化变得容易(只要注释或删除它们),最后添加其他字段也更容易(只要添加一行)。
如果你利用 iota 来使用自定义的整数枚举类型,务必要为其添加 String() 方法。例如,像这样:
type State int |
如果你创建了这个类型的一个变量,然后输出,会得到一个整数(http://play.golang.org/p/V5VVFB05HB):
func main() { |
除非你回顾常量定义,否则这里的0看起来毫无意义。只需要为State类型添加String()方法就可以修复这个问题(http://play.golang.org/p/ewMKl6K302):
func (s State) String() string { |
新的输出是:state: Running。显然现在看起来可读性好了很多。在你调试程序的时候,这会带来更多的便利。同时还可以在实现 MarshalJSON()、UnmarshalJSON() 这类方法的时候使用同样的手段。
在前面的例子中同时也产生了一个我已经遇到过许多次的 bug。假设你有一个新的结构体,有一个State字段:
type T struct { |
现在如果基于 T 创建一个新的变量,然后输出,你会得到奇怪的结果(http://play.golang.org/p/LPG2RF3y39):
func main() { |
看到 bug 了吗?State字段没有初始化,Go 默认使用对应类型的零值进行填充。由于State是一个整数,零值也就是0,但在我们的例子中它表示Running。
那么如何知道 State 被初始化了?还是它真得是在Running模式?没有办法区分它们,那么这就会产生未知的、不可预测的 bug。不过,修复这个很容易,只要让 iota 从 +1 开始(http://play.golang.org/p/VyAq-3OItv):
const ( |
现在t变量将默认输出Unknown,不是吗? :)
func main() { |
不过让 iota 从零值开始也是一种解决办法。例如,你可以引入一个新的状态叫做Unknown,将其修改为:
const ( |
我已经看过很多代码例如(http://play.golang.org/p/8Rz1EJwFTZ):
func bar() (string, error) { |
然而,你只需要:
func bar() (string, error) { |
更简单也更容易阅读(当然,除非你要对某些内部的值做一些记录)。
将 slice 或 map 定义成自定义类型可以让代码维护起来更加容易。假设有一个Server类型和一个返回服务器列表的函数:
type Server struct { |
现在假设需要获取某些特定名字的服务器。需要对 ListServers() 做一些改动,增加筛选条件:
// ListServers 返回服务器列表。只会返回包含 name 的服务器。空的 name 将会返回所有服务器。 |
现在可以用这个来筛选有字符串Foo的服务器:
func main() { |
显然这个函数能够正常工作。不过它的弹性并不好。如果你想对服务器集合引入其他逻辑的话会如何呢?例如检查所有服务器的状态,为每个服务器创建一个数据库记录,用其他字段进行筛选等等……
现在引入一个叫做Servers的新类型,并且修改原始版本的 ListServers() 返回这个新类型:
type Servers []Server |
现在需要做的是只要为Servers类型添加一个新的Filter()方法:
// Filter 返回包含 name 的服务器。空的 name 将会返回所有服务器。 |
现在可以针对字符串Foo筛选服务器:
func main() { |
哈!看到你的代码是多么的简单了吗?还想对服务器的状态进行检查?或者为每个服务器添加一条数据库记录?没问题,添加以下新方法即可:
func (s Servers) Check() |
有时对于函数会有一些重复劳动,例如锁/解锁,初始化一个新的局部上下文,准备初始化变量等等……这里有一个例子:
func foo() { |
如果你想要修改某个内容,你需要对所有的都进行修改。如果它是一个常见的任务,那么最好创建一个叫做withContext的函数。这个函数的输入参数是另一个函数,并用调用者提供的上下文来调用它:
func withLockContext(fn func()) { |
只需要将之前的函数用这个进行封装:
func foo() { |
不要光想着加锁的情形。对此来说最好的用例是数据库链接。现在对 withContext 函数作一些小小的改动:
func withDBContext(fn func(db DB) error) error { |
如你所见,它获取一个连接,然后传递给提供的参数,并且在调用函数的时候返回错误。你需要做的只是:
|
你在考虑一个不同的场景,例如作一些预初始化?没问题,只需要将它们加到withDBContext就可以了。这对于测试也同样有效。
这个方法有个缺陷,它增加了缩进并且更难阅读。再次提示,永远寻找最简单的解决方案。
如果你重度使用 map 读写数据,那么就为其添加 getter 和 setter 吧。通过 getter 和 setter 你可以将逻辑封分别装到函数里。这里最常见的错误就是并发访问。如果你在某个 goroutein 里有这样的代码:
m["foo"] = bar |
还有这个:
delete(m, "foo") |
会发生什么?你们中的大多数应当已经非常熟悉这样的竞态了。简单来说这个竞态是由于 map 默认并非线程安全。不过你可以用互斥量来保护它们:
mu.Lock() |
以及:
mu.Lock() |
假设你在其他地方也使用这个 map。你必须把互斥量放得到处都是!然而通过 getter 和 setter 函数就可以很容易的避免这个问题:
func Put(key, value string) { |
使用接口可以对这一过程做进一步的改进。你可以将实现完全隐藏起来。只使用一个简单的、设计良好的接口,然后让包的用户使用它们:
type Storage interface { |
这只是个例子,不过你应该能体会到。对于底层的实现使用什么都没关系。不光是使用接口本身很简单,而且还解决了暴露内部数据结构带来的大量的问题。
但是得承认,有时只是为了同时对若干个变量加锁就使用接口会有些过分。理解你的程序,并且在你需要的时候使用这些改进。
抽象永远都不是容易的事情。有时,最简单的就是你已经实现的方法。要知道,不要让你的代码看起来很聪明。Go 天生就是个简单的语言,在大多数情况下只会有一种方法来作某事。简单是力量的源泉,也是为什么在人的层面它表现的如此有弹性。
如果必要的话,使用这些基数。例如将[]Server转化为Servers是另一种抽象,仅在你有一个合理的理由的情况下这么做。不过有一些技术,如 iota 从 1 开始计数总是有用的。再次提醒,永远保持简单。
特别感谢 Cihangir Savas、Andrew Gerrand、Ben Johnson 和 Damian Gryski 提供的极具价值的反馈和建议。
阿里云的VPC与其他基于OpenStack的IaaS不同,他的路由只是作为多网段的路由交换,不提供内到外的路由,因此在VPC内的主机除非绑定EIP,否则是无法连接公网的。通过工单询问客服,得到的结论是通过在路由器上添加一个路由,通过一个绑定EIP的主机做NAT上网,通过设置iptables的方式来实现。
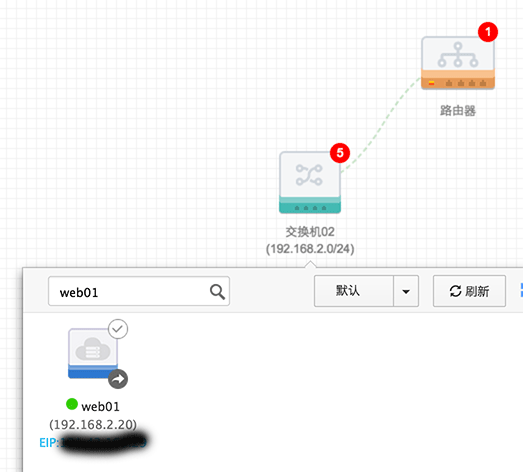
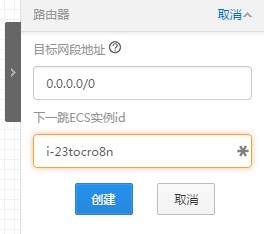
为了让内网服务器借助EIP访问公网,所以设置所有目标地址0.0.0.0/0下一跳都转发到绑定了公网IP的ECS实例上。这里的下一跳ECS不支持搜索,需要提前记号名称:
iptables -t nat -A POSTROUTING -s 192.168.2.0/24 -o eth0 -j MASQUERADE |
注意: ubuntu 14.04 系统保存iptables设置需要安装iptables-persistent包,然后通过
service iptables-persistent save的方式保存配置,安装完iptables-persistent后该服务随系统一起启动并会把保存的配置应用
echo "net.ipv4.ip_forward=1" >> /etc/sysctl.conf && sysctl -p |
# 定义一个空数组 |
说明:
默认数组中的元素是以空格分隔的,如果元素是包含空格的字符串,最好用双引号括起来
shell中的默认分隔符可以通过修改 $IFS变量来设置
# 初始化并赋值数组 |
# 切片 |
- 切片(分片): 直接通过 ${数组名[@或*]:起始位置:长度} 切片原先数组,返回是字符串,中间用“空格”分开,因此如果加上”()”,将得到切片数组,上面例子:c 就是一个新数据。
- 替换: ${数组名[@或*]/查找字符/替换字符} 该操作不会改变原先数组内容,如果需要修改,请重新定义变量并赋值。
在一个多域名的web server环境中,通过分析访问日志,统计最近8小时有用户访问的域名(去重),并显示。
日志格式:X-Forworld-IP User-IP YYYY-MM-DD HH:mm:ss method “URL” HTTP响应码 服务器处理时间 返回大小 “Refer” “浏览器信息” “虚拟主机域名” 真实处理请求的主机
|
由于之前的blog内容过于陈旧,很多文档现在来看会给广大朋友带来困扰,因此决定将之前的所有内容都抛弃,从今天开始重新写!
最近5年由于工作原因也没有顾得上更新blog,近期会有一系列文档更新,都是这五年来的一些工作经验。
由于大家共识的原因,本blog于2015-08-02正式迁移到GitHub
